在 kubernetes 中找出使用 jdk9 及以上版本的应用
 2022-3-30
2022-3-30近日, Spring Cloud (SPEL) 中发现 RCE 0-day 漏洞, 为了排查 kubernetes 中所有存在安全威胁的应用. 特地开发了一个小工具来寻找。该工具基于 golang&client-go 开发, 程序会找出当前集群中所有 Running 的 pods, 然后逐个进入容器,执行 java -version 命令,将命令输出打印到文件中,使用编辑器进行查找检索即可。
2022-3-30近日, Spring Cloud (SPEL) 中发现 RCE 0-day 漏洞, 为了排查 kubernetes 中所有存在安全威胁的应用. 特地开发了一个小工具来寻找。该工具基于 golang&client-go 开发, 程序会找出当前集群中所有 Running 的 pods, 然后逐个进入容器,执行 java -version 命令,将命令输出打印到文件中,使用编辑器进行查找检索即可。
2022-3-28我们知道, 在 kubernetes 中, namespace 的资源限制在 ResourceQuota 中定义, 比如我们控制 default 名称空间使用 1核1G 的资源. 通常来讲, 由于 kubernetes 的资源控制机制, .status.used 中资源的值会小于 .status.hard 中相应资源的值. 但是也有特例. 当我们开始定义了一个较大的资源限制, 待应用部署完毕, 资源占用了很多之后, 这时调低资源限制. 此时就会出现 .status.used 中的值超过 .status.hard 中相应值的情况, 尤其是内存的限制.
2022-3-22以下冷门命令能实现某种具体的功能, 都是在实际工作中摸索总结的经验, 获取到相关的资源名称之后, 就可以配合常用的 kubectl 命令获取其他详细信息.
2022-3-21pod is in the cache, so can’t be assumed, 这是调度器 scheduler 缓存失效导致的异常事件, 大致原因是 pod 已经调度, 并绑定到指定节点, 由于该节点异常导致启动失败, 重新启动 prometheus statefulset, 让集群重新调度, 其实就是将现有到 prometheus pod 副本数将至 0, 再恢复正常即可.
2022-3-21calico-node-4fpgp Readiness probe failed, orphaned pod
2022-3-14周末, 有一台服务器告警: 系统负载过高, 最高的时候都已经到 100 +, 以下是排查&处理的具体过程.
uptime 显示 load average 都在70+
#因为服务器是40核心, 原则上负载40是满负荷, 现在明显存在大量等待的任务. 继续往下分析进程, 看具体那个进程一直在堵塞.
ps -ef 执行到某一个进程就卡住了
#命令执行如下:
...
2022-2-27查看 pod 相关 events 如下:
| |
这是内核bug,建议升级内核
...
2022-2-14本文使用 kubespray 容器部署 kubernetes v1.22, 提供了从国外搬运的离线软件包/容器镜像. 仅需要几步即可部署高可用集群. 所有离线文件都来自官方下载 kubespray 安装过程会进行软件包验证, 放心使用.
注意: 下面配置是适合 kubespray 的配置, 实际配置取决于集群规模.
...
2022-2-8以下是 <实践中总结 Kubernetes 必须了解的核心内容> 主题分享 PPT


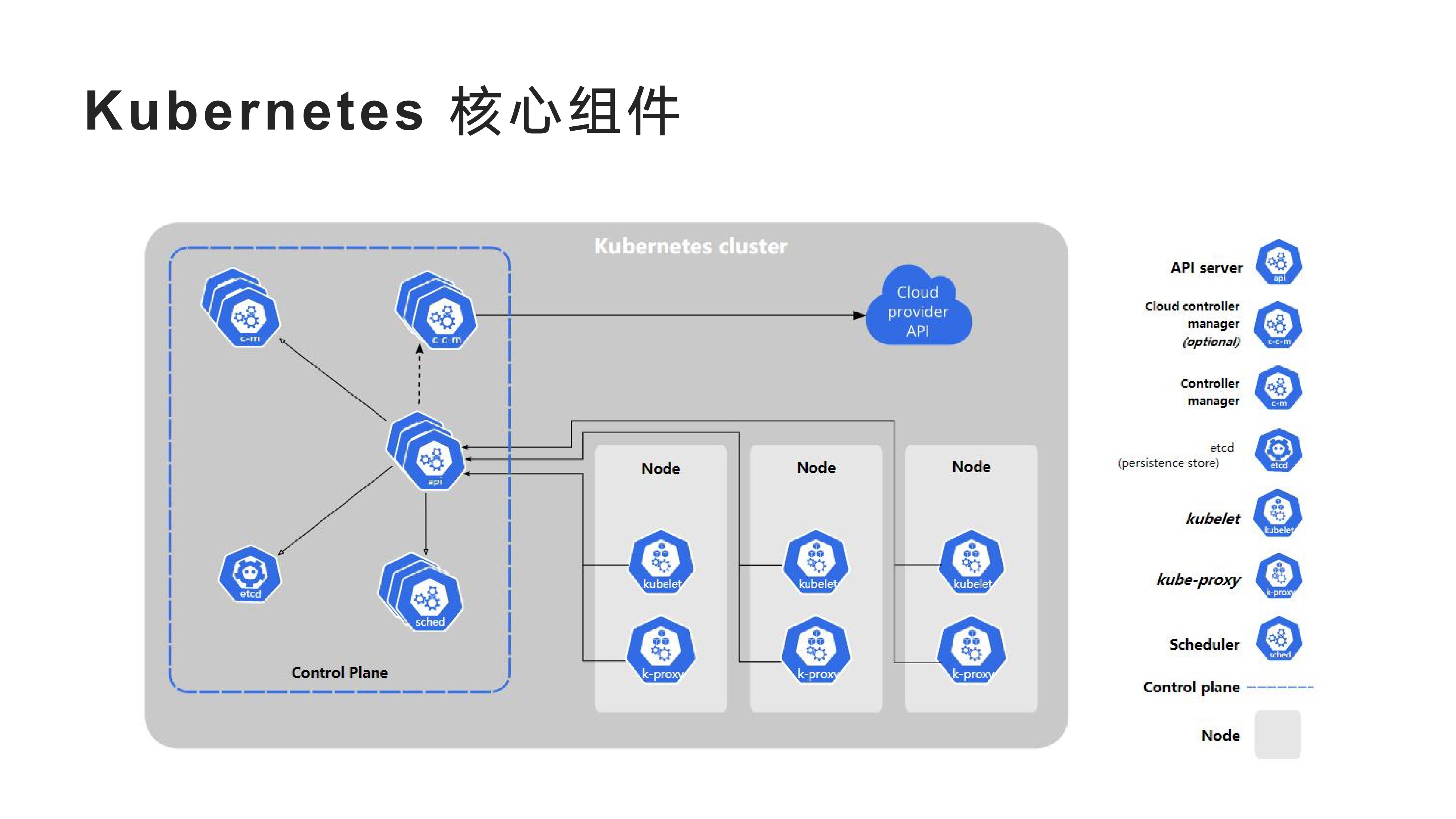


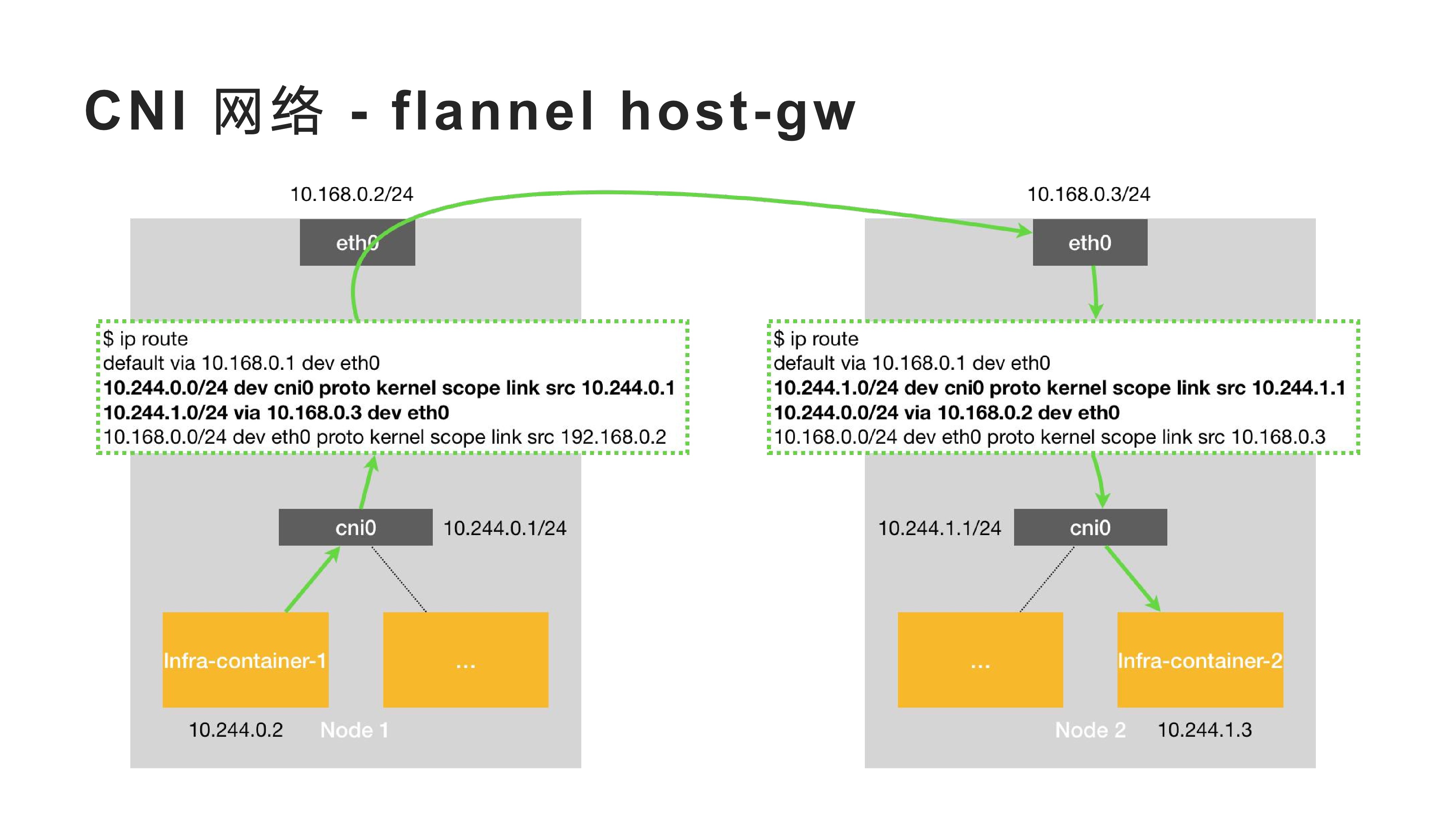
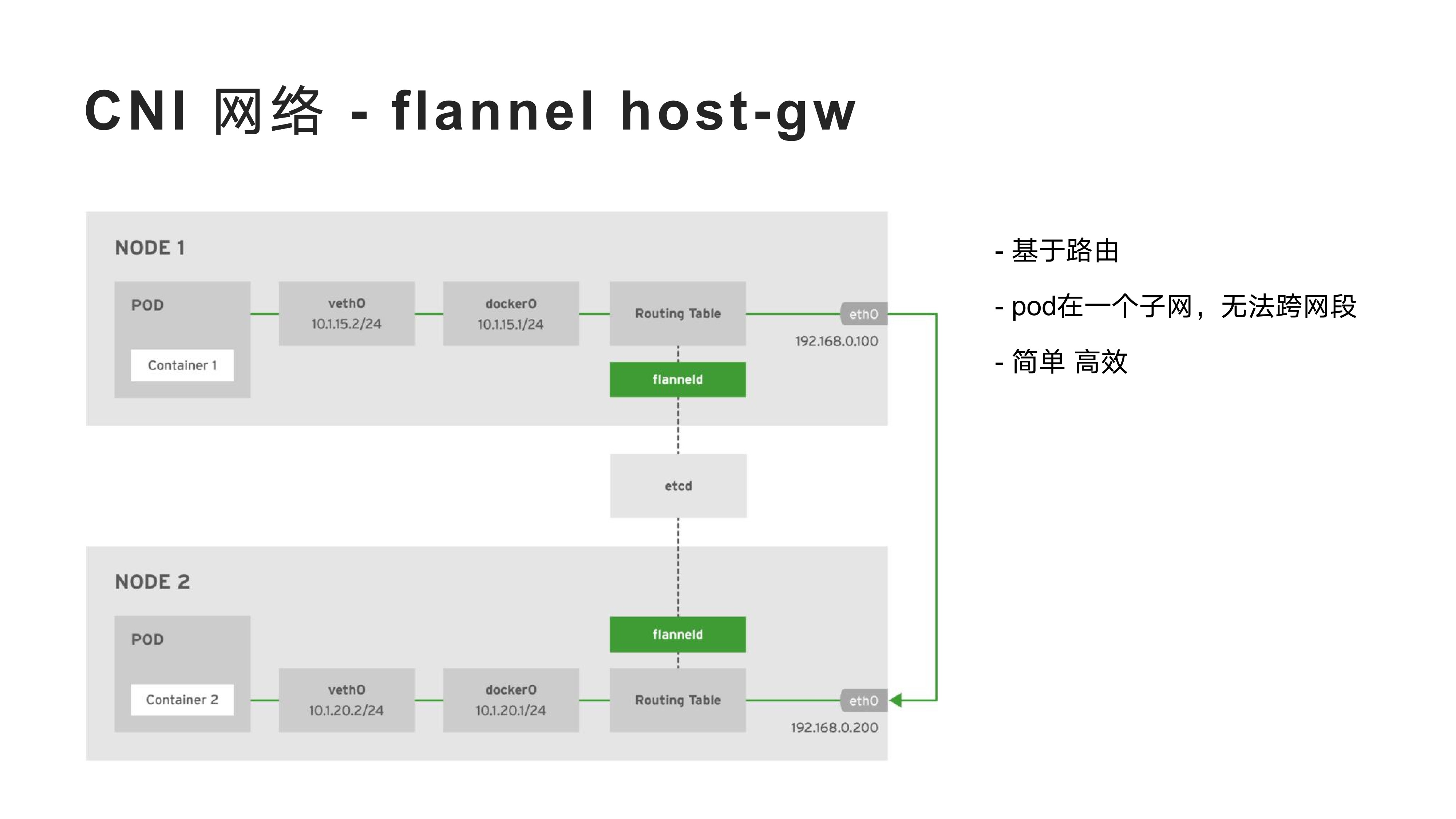
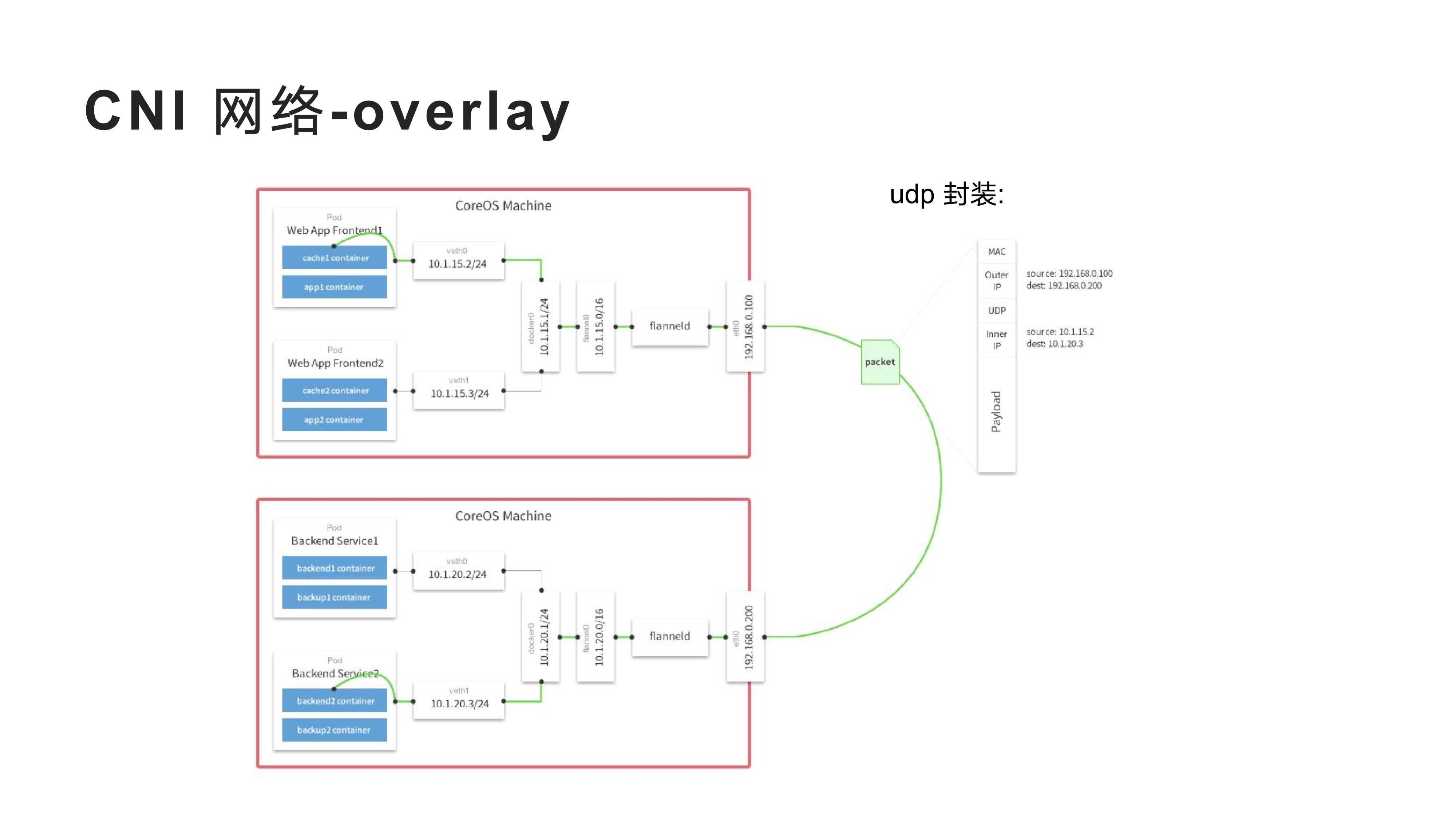
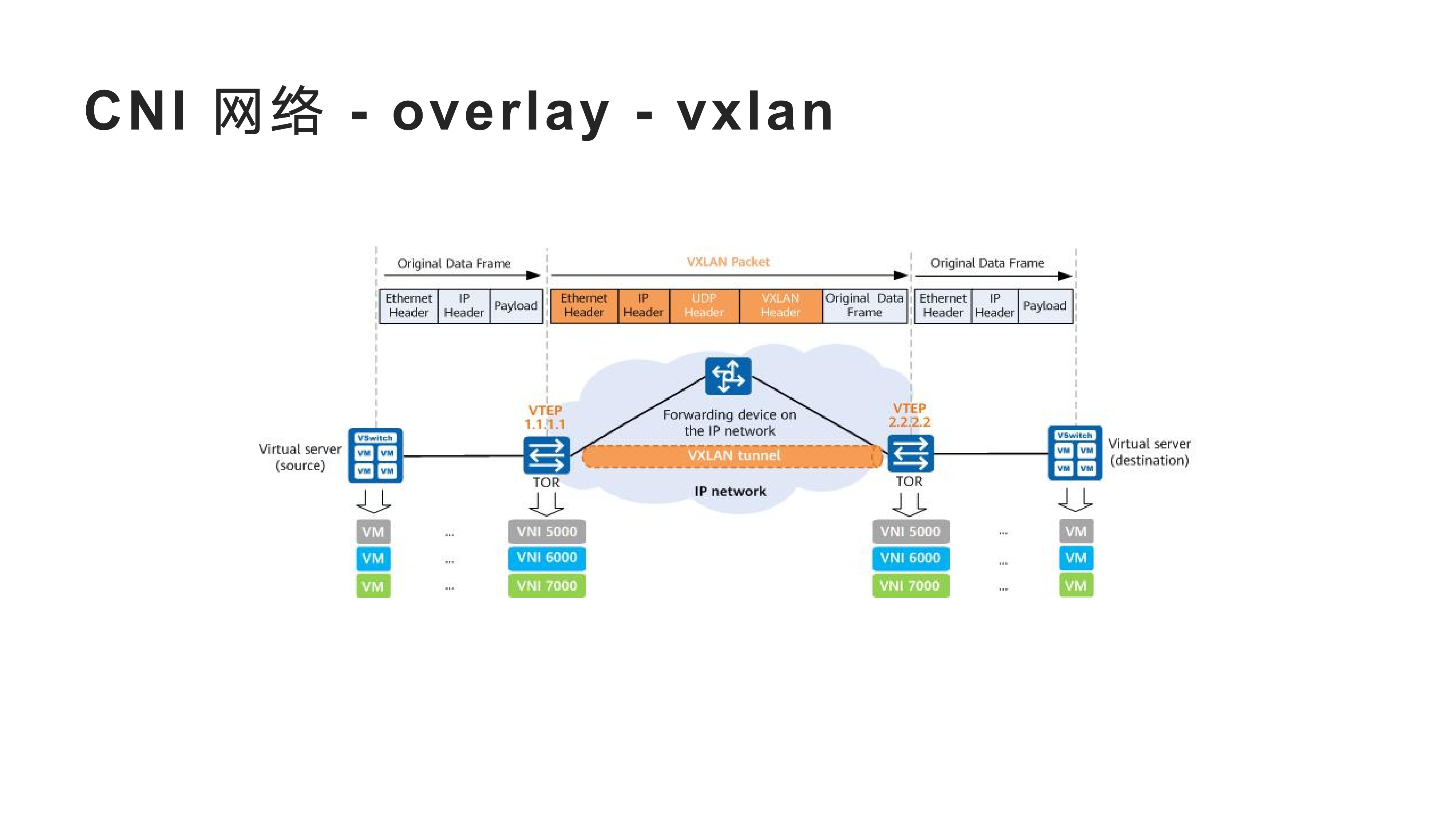
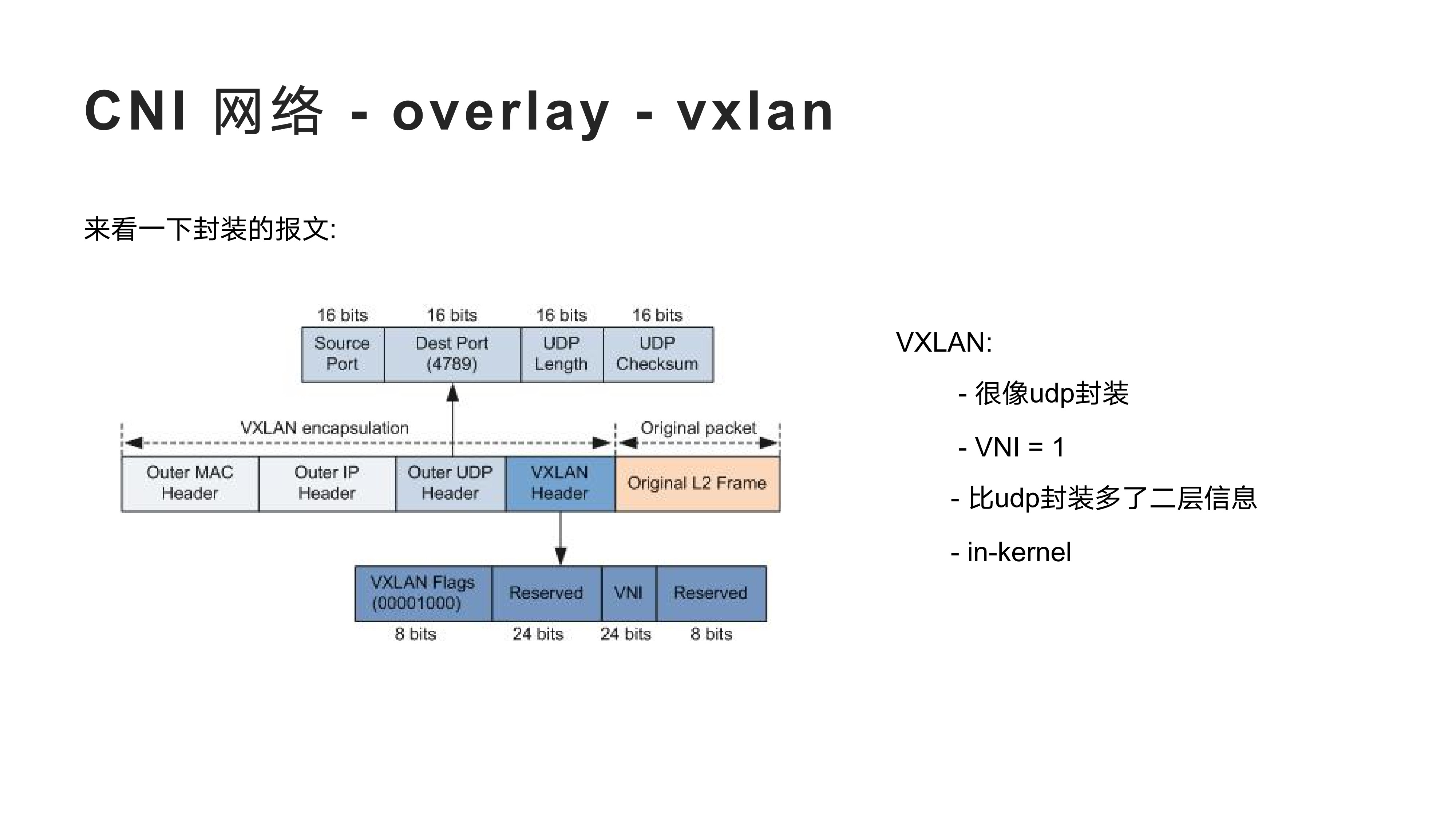




2022-2-8kubernetes 中 pod 的设计是一个伟大的发明, 今天我很有必要去聊一下 pod 和 container, 探究一下它们究竟是什么? kubernetes 官方文档中关于 pod 概念介绍提供了一个完整的解释, 但写的不够详细, 表达过于专业, 但还是很推荐大家阅读一下. 当然这篇文档应该更接地气.
linux 中是没有容器这个概念的, 容器就是 linux 中的普通进程, 它使用了 linux 内核提供的两个重要的特性: namespace & cgroups.
...